Several graph algorithms can help reveal hidden patterns in connected data. These algorithms can be classified into several categories such as approximations (e.g clustering), assortativity (e,g average neighbour degree), communities (e.g K-Clique) and centrality (e.g shortest path). In this blog, we will be looking at one of the most popular shortest path algorithms known as the Dijkstra’s algorithm. We will look at an example table and code implementation for this algorithm. Shortest path algorithm can be relevant in a traffic network situation a user desires to discover the fastest way to move from a source to a destination. It is an iterative algorithm that provides us with the shortest path from an origin node to all other nodes in the graph. This algorithm can work in weighted and unweighted graph scenarios.
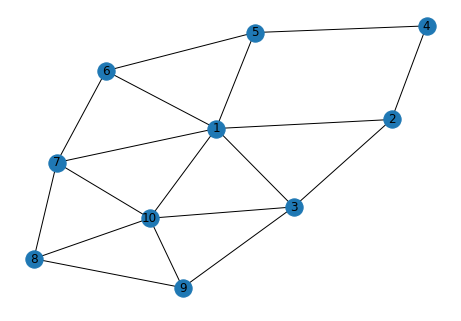
Above is an unweighted graph with ten vertices. In this scenario, the shortest path from one node to another is the fewest number of nodes that will be required to move from the source to the destination.
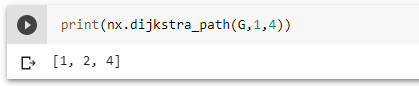
Using the NetworkX library in Python, I was able to check the shortest path from node 1 to 4 and it reveals [1,2,4] as the fastest route. You might be wondering why [1.5.4] was not considered as that is also a two-node movement?
I am now going to check the shortest path from nodes 1 to 8. As you can see below, the route [1,7,8] was chosen when [1,10,8] also contains the same number of paths. The path [1,7,8] has lower values when compared to [1.10.8].

After adding weights to all edges, the shortest path from nodes [1] to [8] was rechecked and route [1, 6, 7, 8] was revealed. This was done with both the Dijkstra and Johnson’s algorithm.

We can also use the Dijkstra’s algorithm to obtain the shortest weighted paths and return dictionaries of predecessors for each node and distance for each node from the source node. In this example, we adopt node [2] as our source and populate a dictionary of the nodes on the path from the source to the destination. It indicates that from node [2] to node [8] there are three paths which will travel from either node 7, 10 or 9.

Path Length
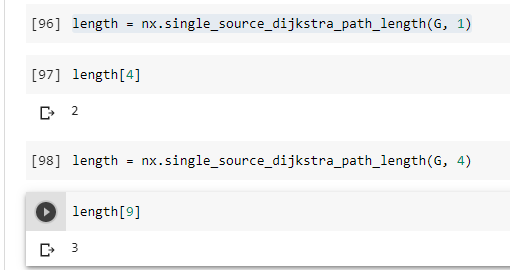
NetworkX also allows you to determine the path length from a source to a destination node. Helping you know the count of the shortest path length. The first example below, from node [1] to [4], reveals the fastest length of 2. While the second example expresses a length of 3 as the shortest distance from nodes [4] to [9].
Non-NetworkX implementation of the Dijkstra’s algorithm
We will now look at the Python implementation of Dijkstra’s algorithm without the NetworkX library.
As a reminder, Djikstra’s is a path-finding algorithm, common in routing and navigation applications. The weight of edges determines the shortest path. The weights can represent cost, time, distance, rate of flow or frequency.
The first step is to create a Graph and initialise the edge and weight dictionaries. When defining the add_edge function, provisions are made to capture an out-degree and an in-degree weight. The from_node and to_node arguments compute the bidirectional weight to determine the shortest path. For example, a path [A, B] with weight 2, and [B, A] with weight 1, will lead to a combined weight of 3 from A to B.
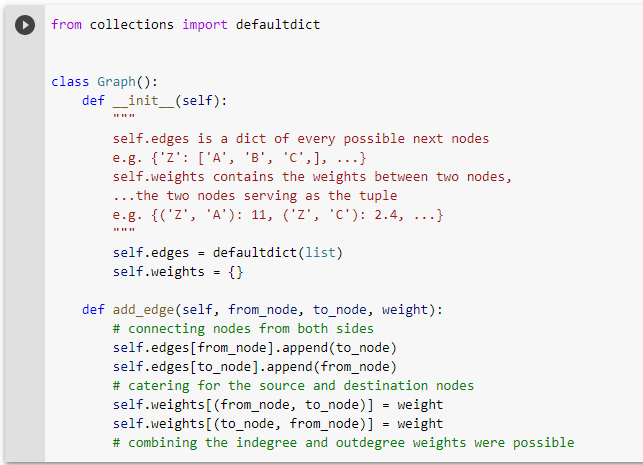
The next step is to create edges between nodes and assign specific weights to these connections. These assigned weights will determine the shortest path.
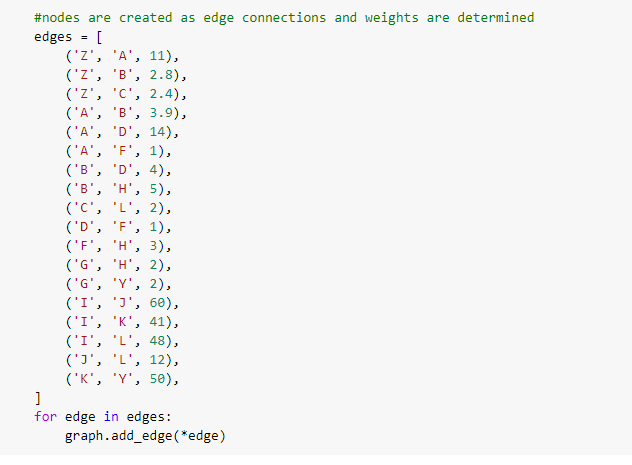
The next step is to utilise the Dijkstra algorithm to find the shortest path. Beginning with the current_node and adding the weight of that node to the next one. The shortest weight equates to the shortest path in this case.
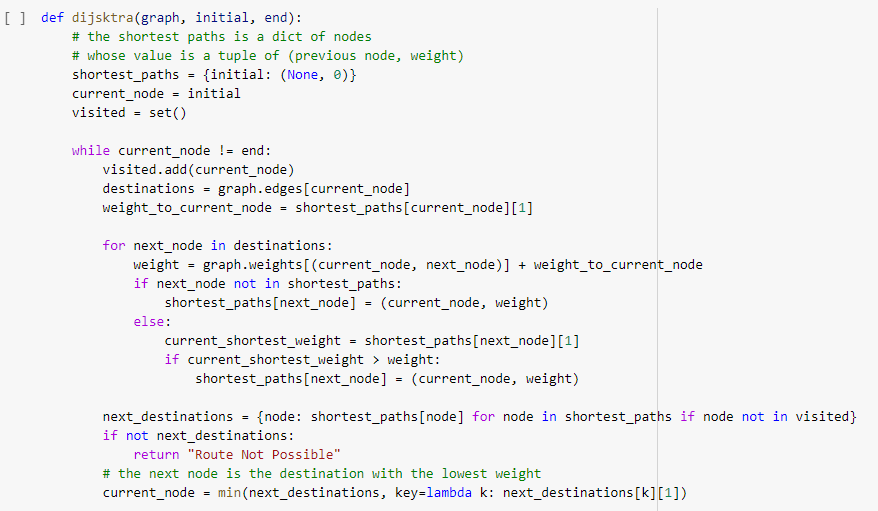
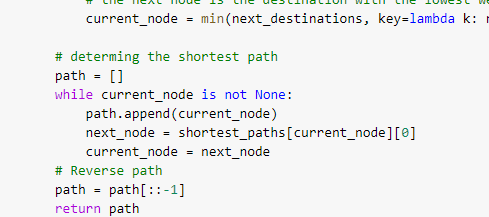
A quick test was run to determine the shortest path from [Z] to [D]. It predicted [Z,B,D] as the shortest path. This is correct as the weight for [Z, B, D] is 6.8 and that of [Z, A, D] is 25.
For the second example, the goal was to discover the shortest path from A to H. The result generated was correct by identifying [A, F, H] as the shortest path with a total weight of 4 when compared to a longer route of [A, B, H] with a weight of 8.9
