Computer applications such as search engines and dialogue systems usually process a large volume of text on a regular basis. These systems have progressed over the years due to advanced word embeddings, progressive research and modern machine learning libraries. It is believed that audio and visual datasets have dense high-dimensional datasets encoded as vectors of a separate raw pixel. Text generated from natural language is usually understood to contain vectors that are sparse when compared to video and visuals.
Vector space models (VSM) embed or represent words in a continuous vector space. In this respect, words that are semantically similar are plotted to nearby points. As representing words as unique and distinct ids can usually lead to a sparsity of data. Going this route will require a large amount of data to be collected to effectively train statistical models. This is why vector representation of words is useful to address the problem of sparsity and enhance semantic interpretation. I ran a search for romantic dinner on Google and one of the people also ask questions was ‘Where can I eat for anniversary?’ We can clearly see the semantic similarity of the term ‘romantic’ and ‘anniversary’ used within the context of food or dining. You would normally expect a distance between the vector representation of these words but from a contextual perspective, an anniversary is usually expected to be romantic as it will involve couples celebrating a milestone in their relationship or marriage.
Words that appear in the same context or have semantic relevance have proximity in the vector representation. There are two different ways vectors are represented from text and they are count-based and predictive methods.
The Count-based Method in Vector Representation
The first form of word embeddings is the count-based method. The count-based method views a target word by the nature of words that co-occur with the word in a multiple of contexts. This is determined using some form of co-occurrence estimation. In this case, the meaning of a word is conceived by the words that co-occur with that word in a variety of scenarios.
A quick search for possible words that occur around the term ‘basketball coach’ from the Bleacher Report Sports website revealed some unsurprising named entities and terms.
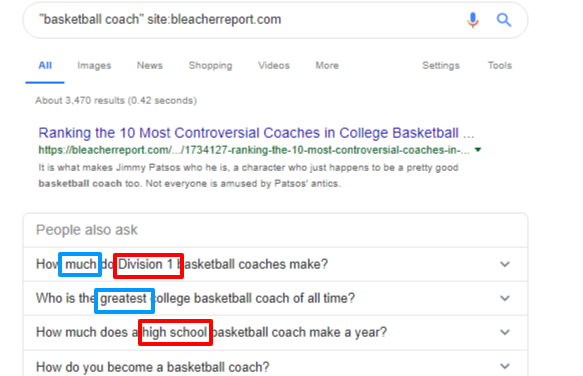
It becomes clear that the terms around the tier of league usually co-occurs with basketball coach. Terms such as Division 1 and high school highlights that information. Other related terms could be the NBA, name of the professional or school athletic club. As I ran excerpt from a Bleacher Report’s article in the AllenNLP fine-grained named entity visualisation tool to understand some other related terms. Date, name of the coach and sports team or institution can co-occur with the term basketball head in the same sentence. There are also terms that highlight the hierarchical nature of the term ‘basketball coach.’ Some of these terms are head, lead and assistant. With these terms comes responsibility, reward and consequences. It is not shocking to see terms such as firing, sacking and remuneration related phrases like ‘how much?’

In evaluating the suitability or strength of the co-occurrence of two words, various techniques have been suggested and these include log likelihood, ratio (LLR), χ 2 measure and the pointwise mutual information. The Oxford English Dictionary (The Second Edition) is believed to contain about 171,476 active words and 47,156 dated words. With Count-based vector representation approaches, among all the words in the present day vocabulary, only about 29 words will co-occur with a target word.
The count-based approaches for vector representation are believed to be fast in training. These methods are also expected to efficiently use statistics in the embedding and prediction of words. On a less positive note, they are viewed as the best for capturing word similarity. These word embedding methods have disproportionate importance to large counts. One of the most popular count-based methods is Latent Semantic Analysis (LSA) or also viewed as Latent Semantic Indexing. LSA is a word – document co-occurrence matrix, as a co-occurrence matrix, it could have downsides to capturing new words or sparsity of words. To address this drawback, count-based vector representations utilise feature reduction approaches like Singular Value Decomposition (SVD) as a post-processing step in the prediction process.
Prediction-based word vectorisation methods
Prediction based approaches for word vectorisation seem to have better performance across a variety of NLP domains such as named entity recognition, machine translation and role labelling. These methods tend to have lower dimensions leading to better dense word representation. Some of the predictive methods are RNN (Recursive neural network), NLM (Neural network language model) and the popular Word2vec model developed by Tomas Mikolov and a group of Google researchers.
These predictive-based vectorisation methods produce lower dimensions and account for rich and dense word representations. Word2Vec have two algorithms – the Continuous Bag of Words (CBOW) and the Skip Gram model. With these algorithms come two training methods – hierarchical Softmax and negative sampling. The Continuous Bag of Words (CBOW) method predicts the centre word based on the context words. With Skip Gram, the surrounding words are predicted based on the centre words. Each word has two vector representation, one vector is for the centre word and the other for the context terms. Overall, Word2Vec improves the objective function by placing similar words. The predictive-based count methods generate improved performance and can capture complex patterns.
On the downside, these algorithms are believed to have efficient use of statistics and scale with corpus size.
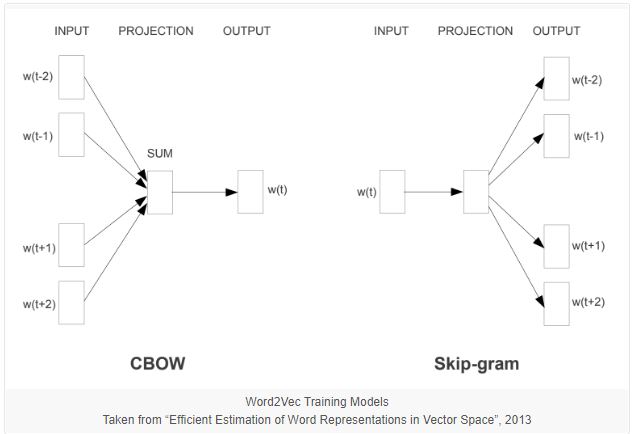
Source: Machinelearningmastery.com