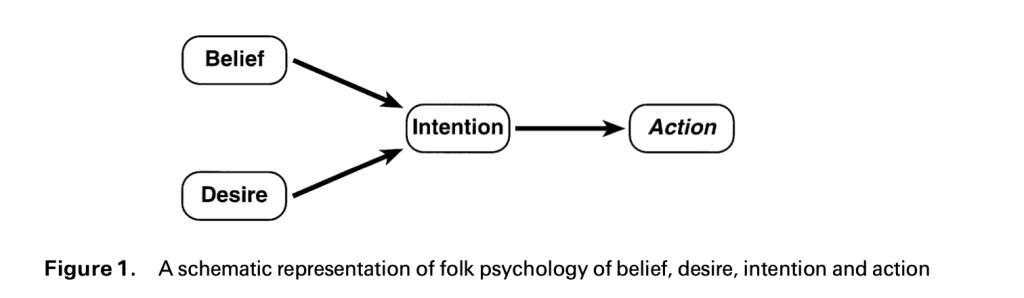
Search marketing has traditionally viewed products and services through the lens of keywords. However, people rarely purchase products for the product itself. They buy them because of a problem they are trying to solve, an outcome they hope to achieve, or a broader set of circumstances influencing their decisions.
A product is often just one part of a much larger story. It exists within a network of causes, motivations, situations, behaviours, and desired outcomes. To truly understand the value of a product or service, brands must understand the wider context in which it exists and the role it plays in a customer’s journey. Doing so requires a more deliberate and holistic perspective.
This is where Meaning Engineering comes in.
Meaning Engineering is the process of understanding and representing the network of causes, contexts, functions, situations, and desired outcomes that give meaning to a product or service from the customer’s perspective.
Unlike traditional SEO, which often begins with keywords, Meaning Engineering starts with concepts and the relationships that define them. Keywords become downstream expressions of those concepts rather than the starting point.
Continue reading